A Payload CMS plugin that adds vector search capabilities to your collections. Perfect for building RAG (Retrieval-Augmented Generation) applications and semantic search features.
- 🔍 Semantic Search: Vectorize any collection for intelligent content discovery
- 🚀 Realtime: Documents are automatically vectorized when created or updated in realtime, and vectors are deleted as soon as the document is deleted.
- 🧵 Bulk embedding: Run "Embed all" batches that backfill only documents missing the current
embeddingVersionsince the last bulk run in order to save money. - 🔌 Database Adapters: Pluggable architecture supporting different database backends
- ⚡ Background Processing: Uses Payload's job system for non-blocking vectorization
- 🎯 Flexible Chunking: Drive chunk creation yourself with
toKnowledgePoolfunctions so you can combine any fields or content types - 🧩 Extensible Schema: Attach custom
extensionFieldsto the embeddings collection and persist values per chunk and use for querying. - 🌐 REST API: Built-in vector-search endpoint with Payload-style
wherefiltering and configurable limits - 🏊 Multiple Knowledge Pools: Separate knowledge pools with independent configurations and needs.
This plugin requires a database adapter for vector storage. Available adapters:
| Adapter | Package | Database | Documentation |
|---|---|---|---|
| PostgreSQL | @payloadcms-vectorize/pg |
PostgreSQL with pgvector | README |
See adapters/README.md for information on creating custom adapters.
- Payload CMS 3.x (tested on 3.69.0, previously tested on 3.37.0)
- A supported database with vector capabilities (see adapters above)
- Node.js 18+
# Install the core plugin
pnpm add payloadcms-vectorize
# Install a database adapter (e.g., PostgreSQL)
pnpm add @payloadcms-vectorize/pg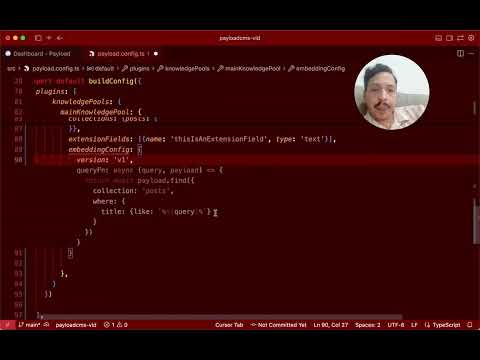
First, configure your database adapter. See the adapter-specific documentation:
- PostgreSQL: See @payloadcms-vectorize/pg README for pgvector setup, schema initialization, and migration handling.
import { buildConfig } from 'payload'
import type { Payload } from 'payload'
import { postgresAdapter } from '@payloadcms/db-postgres'
import { createPostgresVectorIntegration } from '@payloadcms-vectorize/pg'
import payloadcmsVectorize from 'payloadcms-vectorize'
import type { ToKnowledgePoolFn } from 'payloadcms-vectorize'
// Configure your embedding functions
const embedDocs = async (texts: string[]) => {
// Your embedding logic here
return texts.map((text) => /* vector array */)
}
const embedQuery = async (text: string) => {
// Your query embedding logic here
return /* vector array */
}
// Optional chunker helpers (see dev/helpers/chunkers.ts for ideas)
const chunkText = async (text: string, payload: Payload) => {
return /* string array */
}
const chunkRichText = async (richText: any, payload: Payload) => {
return /* string array */
}
// Convert a document into chunks + extension-field values
const postsToKnowledgePool: ToKnowledgePoolFn = async (doc, payload) => {
const entries: Array<{ chunk: string; category?: string; priority?: number }> = []
const titleChunks = await chunkText(doc.title ?? '', payload)
titleChunks.forEach((chunk) =>
entries.push({
chunk,
category: doc.category ?? 'general',
priority: Number(doc.priority ?? 0),
}),
)
const contentChunks = await chunkRichText(doc.content, payload)
contentChunks.forEach((chunk) =>
entries.push({
chunk,
category: doc.category ?? 'general',
priority: Number(doc.priority ?? 0),
}),
)
return entries
}
// Create the database adapter integration
// See adapter documentation for configuration options
const integration = createPostgresVectorIntegration({
mainKnowledgePool: {
dims: 1536, // Vector dimensions
ivfflatLists: 100, // Index parameter
},
})
export default buildConfig({
// ... your existing config
db: postgresAdapter({
extensions: ['vector'],
afterSchemaInit: [integration.afterSchemaInitHook],
// ... your database config
}),
plugins: [
payloadcmsVectorize({
dbAdapter: integration.adapter,
knowledgePools: {
mainKnowledgePool: {
collections: {
posts: {
toKnowledgePool: postsToKnowledgePool,
},
},
extensionFields: [
{ name: 'category', type: 'text' },
{ name: 'priority', type: 'number' },
],
embeddingConfig: {
version: 'v1.0.0',
queryFn: embedQuery,
realTimeIngestionFn: embedDocs,
// bulkEmbeddingsFns: { ... } // Optional: for batch API support
},
},
},
// Optional plugin options:
// realtimeQueueName: 'custom-queue',
// endpointOverrides: { path: '/custom-vector-search', enabled: true },
// disabled: false,
// bulkQueueNames: { // Required iff `bulkEmbeddingsFns` included
// prepareBulkEmbedQueueName: ...,
// pollOrCompleteQueueName: ...,
// },
}),
],
jobs: { // Remember to setup your cron for the embedding
autoRun: [
...
],
},
})Important: knowledgePools must have different names than your collections—reusing a collection name for a knowledge pool will cause schema conflicts. (In this example, the knowledge pool is named 'mainKnowledgePool' and a collection named 'main-knowledge-pool' will be created.)
'payloadcms-vectorize/client#EmbedAllButton') to actual React components. Without it, client components referenced in your collection configs won't render.
Run:
- After initial plugin setup and if in production mode.
- If client components (like the "Embed all" button) don't appear in the admin UI
pnpm run generate:importmapNote: Payload automatically generates the import map on startup during development (HMR), so you typically don't need to run this manually in development. However:
- For production builds: You MUST run
pnpm run generate:importmapBEFORE runningpnpm build, otherwise custom components won't be found during the build process. - If client components don't appear: Try manually generating the import map:
pnpm run generate:importmap
See your database adapter's documentation for migration instructions:
- PostgreSQL: See @payloadcms-vectorize/pg README
The plugin automatically creates a /api/vector-search endpoint:
const response = await fetch('/api/vector-search', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
query: 'What is machine learning?', // Required
knowledgePool: 'main', // Required
where: {
category: { equals: 'guides' }, // Optional Payload-style filter
},
limit: 5, // Optional (defaults to 10)
}),
})
const { results } = await response.json()
// Each result contains: id, score, sourceCollection, docId, chunkIndex, chunkText,
// embeddingVersion, and any extensionFields you attached (e.g., category, priority).Alternatively, you can use the local API directly on the Payload instance:
import { getVectorizedPayload } from 'payloadcms-vectorize'
// After initializing Payload, get the vectorized payload object
const payload = await getPayload({ config, cron: true })
const vectorizedPayload = getVectorizedPayload(payload)
if (vectorizedPayload) {
const results = await vectorizedPayload.search({
query: 'What is machine learning?',
knowledgePool: 'main',
where: {
category: { equals: 'guides' },
},
limit: 5,
})
// results is an array of VectorSearchResult
}| Option | Type | Required | Description |
|---|---|---|---|
knowledgePools |
Record<KnowledgePool, KnowledgePoolDynamicConfig> |
✅ | Knowledge pools and their configurations |
realtimeQueueName |
string |
❌ | Custom queue name for realtime vectorization jobs |
bulkQueueNames |
{prepareBulkEmbedQueueName: string, pollOrCompleteQueueName: string} |
❌ | Queue names for bulk embedding jobs (required if any pool uses bulk ingest) |
endpointOverrides |
object |
❌ | Customize the search endpoint |
disabled |
boolean |
❌ | Disable plugin, except embeddings deletions, while keeping schema |
Knowledge pools are configured in two steps:
1. Static Config (passed to your database adapter's integration factory):
Static configuration options vary by database adapter. See your adapter's documentation for available options:
- PostgreSQL:
dims,ivfflatLists- See @payloadcms-vectorize/pg README
The embeddings collection name will be the same as the knowledge pool name.
2. Dynamic Config (passed to payloadcmsVectorize):
collections:Record<string, CollectionVectorizeOption>- Collections and their configs (optionalshouldEmbedFnfilter + requiredtoKnowledgePoolchunker)extensionFields?:Field[]- Optional fields to extend the embeddings collection schemaembeddingConfig: Embedding configuration object:version:string- Version string for tracking model changesqueryFn:EmbedQueryFn- Function to embed search queriesrealTimeIngestionFn?:EmbedDocsFn- Function for real-time embedding on document changesbulkEmbeddingsFns?: Streaming bulk embedding callbacks (see below)
If realTimeIngestionFn is provided, documents are embedded immediately on create/update.
If only bulkEmbeddingsFns is provided (no realTimeIngestionFn), embedding only happens via manual bulk runs.
If neither is provided, embedding is disabled for that pool.
Note: Embedding deletion cannot be disabled. When a source document is deleted, all its embeddings are automatically deleted from all knowledge pools that contain that collection, regardless of how the embeddings were created (bulk or real-time). This behavior ensures data consistency and cannot be configured.
The bulk embedding API is designed for large-scale embedding using provider batch APIs (like Voyage AI). Bulk runs are never auto-queued - they must be triggered manually via the admin UI or API.
In order to get bulk embeddings to interface with your provider, you must define the following three callbacks per knowledge pool (the functions do not have to be unique so you can re-use across knowledge pools).
type BulkEmbeddingsFns = {
addChunk: (args: AddChunkArgs) => Promise<BatchSubmission | null>
pollOrCompleteBatch: (args: PollOrCompleteBatchArgs) => Promise<PollBulkEmbeddingsResult>
onError?: (args: OnBulkErrorArgs) => Promise<void>
}The plugin streams chunks to your callbacks one at a time; the callback is called for each chunk. You manage your own accumulation and decide when to submit based on file size.
type AddChunkArgs = {
chunk: { id: string; text: string }
isLastChunk: boolean
}
type BatchSubmission = {
providerBatchId: string
}About the chunk.id field:
- Plugin-generated: The plugin automatically generates a unique
idfor each chunk (format:${collectionSlug}:${docId}:${chunkIndex}). You don't need to create it. - Purpose: The
idis used to correlate embedding outputs back to their original inputs, ensuring each embedding is correctly associated with its source document and chunk. - Usage: When submitting batches to your provider, you must pass this
idalong with the text (e.g., ascustom_idin Voyage AI's batch API). This allows your provider to return theidwith each embedding result.
Return values:
null- "I'm accumulating this chunk, not ready to submit yet"{ providerBatchId }- "I just submitted a batch to my provider"
When you return a submission, the plugin assumes all chunks currently in pendingChunks were submitted. The plugin tracks chunks and creates batch records based on this assumption.
About isLastChunk:
isLastChunk=trueindicates this is the final chunk in the run- Use this to flush any remaining accumulated chunks before the run completes
Example implementation:
let accumulated: BulkEmbeddingInput[] = []
const LINE_LIMIT = 100_000 // e.g., Voyage AI's limit
addChunk: async ({ chunk, isLastChunk }) => {
// Add current chunk to accumulation first
accumulated.push(chunk)
// Check if we've hit the line limit (after adding current chunk)
if (accumulated.length === LINE_LIMIT) {
const result = await submitToProvider(accumulated)
accumulated = [] // Clear for next batch
return { providerBatchId: result.id }
}
// Last chunk? Must flush everything
if (isLastChunk && accumulated.length > 0) {
const result = await submitToProvider(accumulated)
accumulated = []
return { providerBatchId: result.id }
}
return null
}Note: If a single chunk exceeds your provider's file size or line limit, you'll need to handle that edge case in your implementation (e.g., skip it, split it, or fail gracefully).
Called repeatedly until the batch reaches a terminal status. When the batch completes, stream the outputs via the onChunk callback.
type PollOrCompleteBatchArgs = {
providerBatchId: string // You provided it in the earlier step when you submitted a batch.
onChunk: (chunk: BulkEmbeddingOutput) => Promise<void>
}
type PollBulkEmbeddingsResult = {
status: 'queued' | 'running' | 'succeeded' | 'failed' | 'canceled'
counts?: { inputs?: number; succeeded?: number; failed?: number }
error?: string
}
type BulkEmbeddingOutput = {
id: string // Must match the chunk.id from addChunk
embedding?: number[]
error?: string
}How it works:
- The plugin calls
pollOrCompleteBatchrepeatedly for each batch - While the batch is in progress, return the status (
queuedorrunning) without callingonChunk - When the batch completes, stream each embedding result by calling
onChunkfor each output, then return{ status: 'succeeded' } - If the batch fails, return
{ status: 'failed', error: '...' }without callingonChunk
About the id field in outputs:
- Correlation: The
idin eachBulkEmbeddingOutputmust match thechunk.idthat was passed toaddChunk. This is how the plugin correlates outputs back to their original inputs. - Extraction: When processing your provider's response, extract the
idthat you originally sent (e.g., from Voyage'scustom_idfield) and include it in the returnedBulkEmbeddingOutput. - Example: If you sent
{ custom_id: "posts:123:0", input: [...] }to your provider, extractresult.custom_idfrom the response and callawait onChunk({ id: result.custom_id, embedding: [...] }).
Called when the bulk run fails OR when there are partial chunk failures. Use this to clean up provider-side resources (delete files, cancel batches) and handle failed chunks. The run can be re-queued after cleanup.
type FailedChunkData = {
collection: string // Source collection slug
documentId: string // Source document ID
chunkIndex: number // Index of the chunk within the document
}
type OnBulkErrorArgs = {
providerBatchIds: string[]
error: Error
/** Data about chunks that failed during completion */
failedChunkData?: FailedChunkData[]
/** Count of failed chunks */
failedChunkCount?: number
}Error handling behavior:
- Batch failures: If any batch fails during polling, the entire run fails and
onErroris called. - Partial chunk failures: If individual chunks fail during completion (e.g., provider returned an error for specific inputs), the run still succeeds but
onErroris called withfailedChunkDataandfailedChunkCount. - Failed chunk data: The
failedChunkDataarray contains structured information about failed chunks, includingcollection,documentId, andchunkIndex. This data is also stored in the run record (failedChunkDatafield) for later inspection and potential retry. - Partial success: Successful embeddings are still written even when some chunks fail. Only the failed chunks are skipped.
The plugin uses separate Payload jobs for reliability with long-running providers:
prepare-bulk-embedding: A coordinator job fans out one worker per collection. Each worker streams through documents, calls youraddChunkfor each chunk, and creates batch records. WhenbatchLimitis set on a collection, workers paginate and queue continuation jobs.poll-or-complete-single-batch: Polls a single batch, requeues itself until done, then writes successful embeddings. When all batches for a run are terminal, the run is finalized (partial chunk failures are allowed).
For bulk embedding, you must provide the bulk queue names.
plugins: [
payloadcmsVectorize({
knowledgePools: { /* ... */ },
realtimeQueueName: 'vectorize-realtime', // optional
bulkQueueNames: { // required iff you are using bulk embeddings
prepareBulkEmbedQueueName: 'vectorize-bulk-prepare',
pollOrCompleteQueueName: 'vectorize-bulk-poll',
},
}),
]
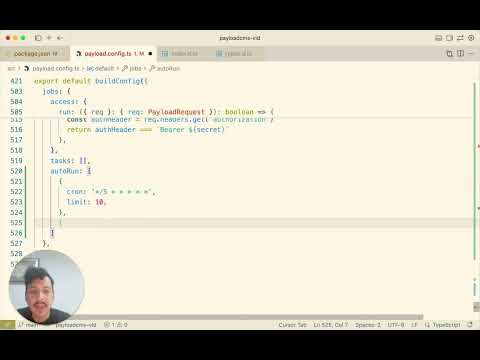
jobs: {
autoRun: [ // Must match
{ cron: '*/5 * * * * *', limit: 10, queue: 'vectorize-realtime' },
{ cron: '0 0 * * * *', limit: 1, queue: 'vectorize-bulk-prepare' },
{ cron: '*/30 * * * * *', limit: 5, queue: 'vectorize-bulk-poll' },
],
}Static configuration changes (like vector dimensions) may require migrations. See your database adapter's documentation for specific instructions:
- PostgreSQL: See @payloadcms-vectorize/pg README
Starts a bulk embedding run for a knowledge pool via HTTP. This is the REST API equivalent of vectorizedPayload.bulkEmbed().
Request Body:
{
"knowledgePool": "default"
}Success Response (202 Accepted):
{
"runId": "123",
"status": "queued"
}Conflict Response (409 Conflict) - when a run is already active:
{
"runId": "456",
"status": "running",
"message": "A bulk embedding run is already running for this knowledge pool. Wait for it to complete or cancel it first.",
"conflict": true
}Error Responses:
400 Bad Request: Missing or invalidknowledgePoolparameter500 Internal Server Error: Server error during processing
Example:
curl -X POST http://localhost:3000/api/vector-bulk-embed \
-H "Content-Type: application/json" \
-d '{"knowledgePool": "default"}'Retries a failed batch from a bulk embedding run via HTTP. This is the REST API equivalent of vectorizedPayload.retryFailedBatch().
Request Body:
{
"batchId": "123"
}Success Response (202 Accepted):
{
"batchId": "123",
"newBatchId": "456",
"runId": "789",
"status": "queued"
}Already Retried Response (202 Accepted) - when batch was already retried:
{
"batchId": "123",
"newBatchId": "456",
"runId": "789",
"status": "queued",
"message": "Batch was already retried. Returning the retry batch."
}Error Responses:
400 Bad Request: Missing or invalidbatchIdparameter, or batch is not in a retriable state404 Not Found: Batch not found409 Conflict: Cannot retry while parent run is still active500 Internal Server Error: Server error during processing
Example:
curl -X POST http://localhost:3000/api/vector-retry-failed-batch \
-H "Content-Type: application/json" \
-d '{"batchId": "123"}'shouldEmbedFn? (doc, payload)– optional filter that runs before the document is queued for embedding. Returnfalseto skip the document entirely (no job is created andtoKnowledgePoolis never called). Works for both real-time and bulk embedding. Defaults to embedding all documents when omitted.toKnowledgePool (doc, payload)– return an array of{ chunk, ...extensionFieldValues }. Each object becomes one embedding row and the index in the array determineschunkIndex.batchLimit? (number)– max documents to fetch per bulk-embed worker job. When set, each page of results becomes a separate job that queues a continuation for the next page. Useful for large collections that would exceed serverless time limits in a single job. Defaults to 1000.
Reserved column names: sourceCollection, docId, chunkIndex, chunkText, embeddingVersion. Avoid reusing them in extensionFields.
Example – skip draft documents:
collections: {
posts: {
shouldEmbedFn: async (doc) => doc._status === 'published',
toKnowledgePool: postsToKnowledgePool,
},
}Use chunker helpers (see dev/helpers/chunkers.ts) to keep toKnowledgePool implementations focused on orchestration. A toKnowledgePool can combine multiple chunkers, enrich each chunk with metadata, and return everything the embeddings collection needs.
const postsToKnowledgePool: ToKnowledgePoolFn = async (doc, payload) => {
const chunks = await chunkText(doc.title ?? '', payload)
return chunks.map((chunk) => ({
chunk,
category: doc.category ?? 'general',
}))
}Because you control the output, you can mix different field types, discard empty values, or inject any metadata that aligns with your extensionFields.
- Each entry returned by
toKnowledgePoolmust be an object with a requiredchunkstring. - If any entry is malformed, the vectorize job fails with
hasError = trueand an error message listing invalid indices. - To retry after fixing your
toKnowledgePoollogic, clearhasErrorandcompletedAt(and setprocessingtofalseif needed) on the failedpayload-jobsrow. The queue runner will pick it up on the next interval.
import { voyageEmbedDocs, voyageEmbedQuery } from 'voyage-ai-provider'
export const embedDocs = async (texts: string[]): Promise<number[][]> => {
const embedResult = await embedMany({
model: voyage.textEmbeddingModel('voyage-3.5-lite'),
values: texts,
providerOptions: {
voyage: { inputType: 'document' },
},
})
return embedResult.embeddings
}
export const embedQuery = async (text: string): Promise<number[]> => {
const embedResult = await embed({
model: voyage.textEmbeddingModel('voyage-3.5-lite'),
value: text,
providerOptions: {
voyage: { inputType: 'query' },
},
})
return embedResult.embedding
}You can see more examples in dev/helpers/embed.ts
POST /api/vector-search
Search for similar content using vector search.
Request Body:
Parameters
query(required): Search query stringknowledgePool(required): Knowledge pool identifier to search inwhere(optional): Payload-styleWhereclause evaluated against the embeddings collection + anyextensionFieldslimit(optional): Maximum results to return (defaults to10)
Response:
{
"results": [
{
"id": "embedding_id",
"score": 0.85,
"sourceCollection": "posts",
"docId": "post_id",
"chunkIndex": 0,
"chunkText": "Relevant text chunk",
"embeddingVersion": "v1.0.0",
"category": "guides", // example extension field
"priority": 4, // example extension field
},
],
}- Each knowledge pool's embeddings list shows an Embed all admin button that triggers a bulk run.
- Import map note: In development (
pnpm dev), Payload auto-generates the import map. For production builds (pnpm build), you must runpnpm run generate:importmapfirst (see Quick Start above). - Bulk runs only include documents with mismatched embedding versions for the pool's current
embeddingConfig.versionfrom the previous bulk run (unless none has been done in which case it embeds all). - Progress is recorded in
vector-bulk-embeddings-runsandvector-bulk-embeddings-batchesadmin UI collections. - You can re-run failed bulk embeddings from
vector-bulk-embeddings-batchesadmin UI and you can link to the failed batches from thevector-bulk-embeddings-runsadmin UI. - Endpoints: POST
/api/vector-bulk-embedand/api/vector-retry-failed-batch
{
"knowledgePool": "main",
}The bulk embedding process has three levels of failure:
- Run level: If any chunk fails during ingestion (toKnowledgePool), the entire run fails and no embeddings are written. This is fully atomic. Your onError is expected to handle clean up from this stage.
- Batch level: If any batch fails during polling, the entire run is marked as failed but embeddings from working batches are written.
- Chunk level: If individual chunks fail during completion (e.g., provider returns errors for specific inputs), the run still succeeds and successful embeddings are written. Failed chunks are tracked in
failedChunkData(with structuredcollection,documentId, andchunkIndexfields) and passed to theonErrorcallback for cleanup.
This design allows for partial success: if 100 chunks are processed and 2 fail, 98 embeddings are written and the 2 failures are tracked for potential retry.
Error Recovery: If a run fails, you can re-queue it. If you provided an onError callback, it will be called with all providerBatchIds so you can clean up provider-side resources before retrying.
If bulkEmbeddingsFns is not provided, the "Embed all" button is disabled.
The plugin provides a getVectorizedPayload(payload) function which returns a 'vectorizedPayload' (an object) with search, queueEmbed, bulkEmbed and retryFailedBatch methods.
Use the getVectorizedPayload function to get the vectorized payload object with all vectorize methods:
import { getVectorizedPayload } from 'payloadcms-vectorize'
const payload = await getPayload({ config, cron: true })
const vectorizedPayload = getVectorizedPayload(payload)
if (vectorizedPayload) {
// Use all vectorize methods
const results = await vectorizedPayload.search({
query: 'search query',
knowledgePool: 'main',
})
await vectorizedPayload.queueEmbed({
collection: 'posts',
docId: 'some-id',
})
await vectorizedPayload.bulkEmbed({
knowledgePool: 'main',
})
}Perform vector search programmatically without making an HTTP request.
Parameters:
params.query(required): Search query stringparams.knowledgePool(required): Knowledge pool identifier to search inparams.where(optional): Payload-styleWhereclause evaluated against the embeddings collection + anyextensionFieldsparams.limit(optional): Maximum results to return (defaults to10)
Returns: Promise<Array<VectorSearchResult>>
Example:
import { getVectorizedPayload } from 'payloadcms-vectorize'
const payload = await getPayload({ config, cron: true })
const vectorizedPayload = getVectorizedPayload<'main'>(payload)
if (vectorizedPayload) {
const results = await vectorizedPayload.search({
query: 'What is machine learning?',
knowledgePool: 'main',
where: {
category: { equals: 'guides' },
},
limit: 5,
})
}Manually queue a vectorization job for a document.
Parameters:
Either:
params.collection(required): Collection slugparams.docId(required): Document ID to fetch and vectorize
Or:
params.collection(required): Collection slugparams.doc(required): Document object to vectorize
Returns: Promise<void>
Example:
import { getVectorizedPayload } from 'payloadcms-vectorize'
const payload = await getPayload({ config, cron: true })
const vectorizedPayload = getVectorizedPayload(payload)
if (vectorizedPayload) {
// Queue by document ID (fetches document first)
await vectorizedPayload.queueEmbed({
collection: 'posts',
docId: 'some-post-id',
})
// Queue with document object directly
await vectorizedPayload.queueEmbed({
collection: 'posts',
doc: {
id: 'some-post-id',
title: 'Post Title',
content: {
/* ... */
},
},
})
}Starts a bulk embedding run for a knowledge pool. This method queues a background job that will process all documents in the knowledge pool's collections, chunk them, and submit them to your embedding provider via the bulkEmbeddingsFns.addChunk callback.
Parameters:
params.knowledgePool(required): The name of the knowledge pool to embed
Returns: Promise<BulkEmbedResult>
Success Response:
{
runId: string // ID of the created bulk embedding run
status: 'queued' // Initial status of the run
}Conflict Response (if a run is already active):
{
runId: string // ID of the existing active run
status: 'queued' | 'running' // Status of the existing run
message: string // Explanation of why a new run wasn't started
conflict: true // Indicates a conflict occurred
}Example:
const result = await vectorizedPayload.bulkEmbed({ knowledgePool: 'default' })
if ('conflict' in result && result.conflict) {
console.log('A run is already active:', result.message)
} else {
console.log('Bulk embed started with run ID:', result.runId)
}Notes:
- Only one bulk embedding run can be active per knowledge pool at a time
- The run will process documents that need embedding (those with mismatched
embeddingVersionor new documents since the last successful run) - Progress can be tracked via the
vector-bulk-embeddings-runsandvector-bulk-embeddings-batchescollections in the admin UI - The run status will progress:
queued→running→succeededorfailed
Retries a failed batch from a bulk embedding run. This method reconstructs the chunks from the batch's metadata, resubmits them to your embedding provider, and creates a new batch record. The original batch is marked as retried and linked to the new batch.
Parameters:
params.batchId(required): The ID of the failed batch to retry
Returns: Promise<RetryFailedBatchResult>
Success Response:
{
batchId: string // ID of the batch being retried
newBatchId: string // ID of the newly created batch
runId: string // ID of the parent run
status: 'queued' // Status of the new batch
message?: string // Optional confirmation message
}Already Retried Response (if batch was already retried):
{
batchId: string // ID of the original batch
newBatchId: string // ID of the existing retry batch
runId: string // ID of the parent run
status: 'queued' // Status of the retry batch
message: string // Message indicating batch was already retried
}Error Response:
{
error: string // Error message
conflict?: true // Present if error is due to a conflict (e.g., run still active)
}Example:
const result = await vectorizedPayload.retryFailedBatch({ batchId: '123' })
if ('error' in result) {
console.error('Failed to retry batch:', result.error)
} else {
console.log(`Batch ${result.batchId} retried. New batch ID: ${result.newBatchId}`)
}Notes:
- Only batches with
failedorretriedstatus can be retried - The parent run must be in a terminal state (
succeededorfailed) - cannot retry while run isqueuedorrunning - If the parent run was
succeededorfailed, it will be reset torunningstatus - The original batch is marked as
retriedand linked to the new batch via theretriedBatchfield - Chunks are reconstructed from the batch's metadata, so metadata must still exist for the retry to work
- If a batch was already retried, calling this method again returns the existing retry batch instead of creating a duplicate
See CHANGELOG.md for release history, migration notes, and upgrade guides.
MIT
Contributions are welcome! Please feel free to submit a Pull Request.
We're especially looking for help adding more database adapters! If you use MongoDB Atlas, SQLite, Pinecone, Qdrant, or any other vector-capable database with Payload CMS, we'd love your help building an adapter. See adapters/README.md for the DbAdapter interface and how to get started. Open an issue to coordinate before starting work.
If you find this plugin useful, please give it a star! Stars help us understand how many developers are using this plugin and directly influence our development priorities. More stars = more features, better performance, and faster bug fixes.
Help us prioritize development by opening issues for:
- Bugs: Something not working as expected
- Feature requests: New functionality you'd like to see
- Improvements: Ways to make existing features better
- Documentation: Missing or unclear information
- Questions: I'll answer through the issues.
The more detailed your issue, the better I can understand and address your needs. Issues with community engagement (reactions, comments) get higher priority!
Thank you for the stars! The following updates have been completed:
- Multiple Knowledge Pools: You can create separate knowledge pools with independent configurations and embedding functions. Each pool operates independently, allowing you to organize your vectorized content by domain, use case, or any other criteria that makes sense for your application.
- Database Adapter Architecture: Pluggable adapter system allowing support for different database backends.
- More expressive queries: Added ability to change query limit, search on certain collections or certain fields
- Bulk embed all: Batch backfills with admin button, provider callbacks, and run tracking.
The following features are planned for future releases based on community interest and stars:
- MongoDB adapter: Add a
@payloadcms-vectorize/mongodbadapter for MongoDB Atlas Vector Search - Vercel support: Optimized deployment and configuration for Vercel hosting
Want to see these features sooner? Star this repository and open issues for the features you need most!
{ "query": "Your search query", "knowledgePool": "main", "where": { "category": { "equals": "guides" }, "priority": { "gte": 3 }, }, "limit": 5, }