Manual reboot required #42
Description
Not quite sure what is going on here but every machine seems to be needing some reboot after a while. Here's what it's doing:
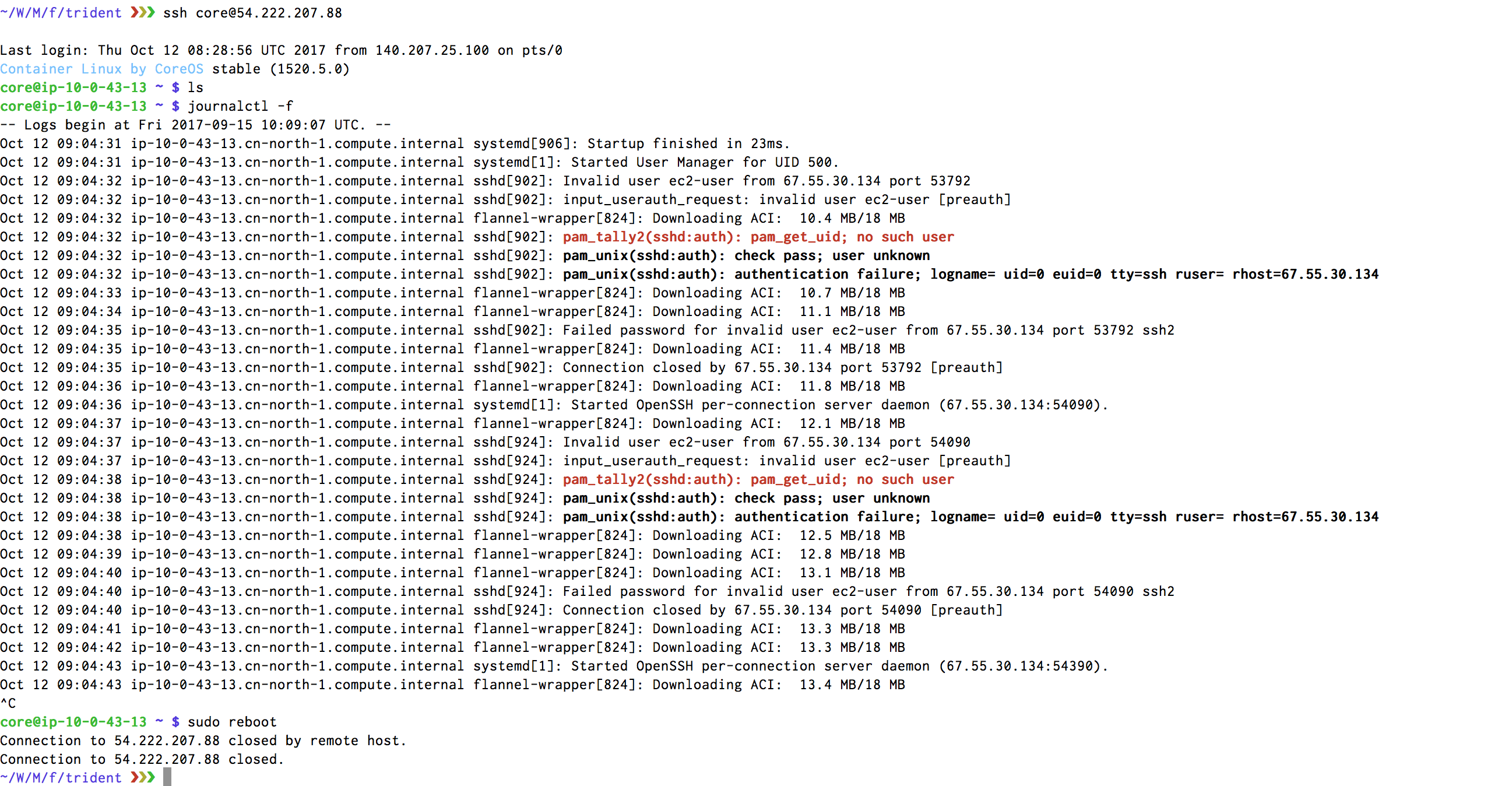
Each node today has encountered this issue, master, edge and worker. However all three of them seems to be fine after a manual reboot.